如果说 LLM (大语言模型) 解决了“思考”的问题,那么 OpenAI Operator (及其背后的 CUA 模型) 则解决了“行动”的问题。它让 AI 能够直接操作我们熟悉的图形化界面,实现从“对话”到“自动化任务”的跨越。
一、 技术架构:Agent Loop 的闭环
Operator 的核心在于一个被称为 Agent Loop 的持续反馈过程。不同于传统的网页爬虫(依赖解析 HTML 源码),Operator 的思维模式更接近人类:它通过“看”屏幕来操作。
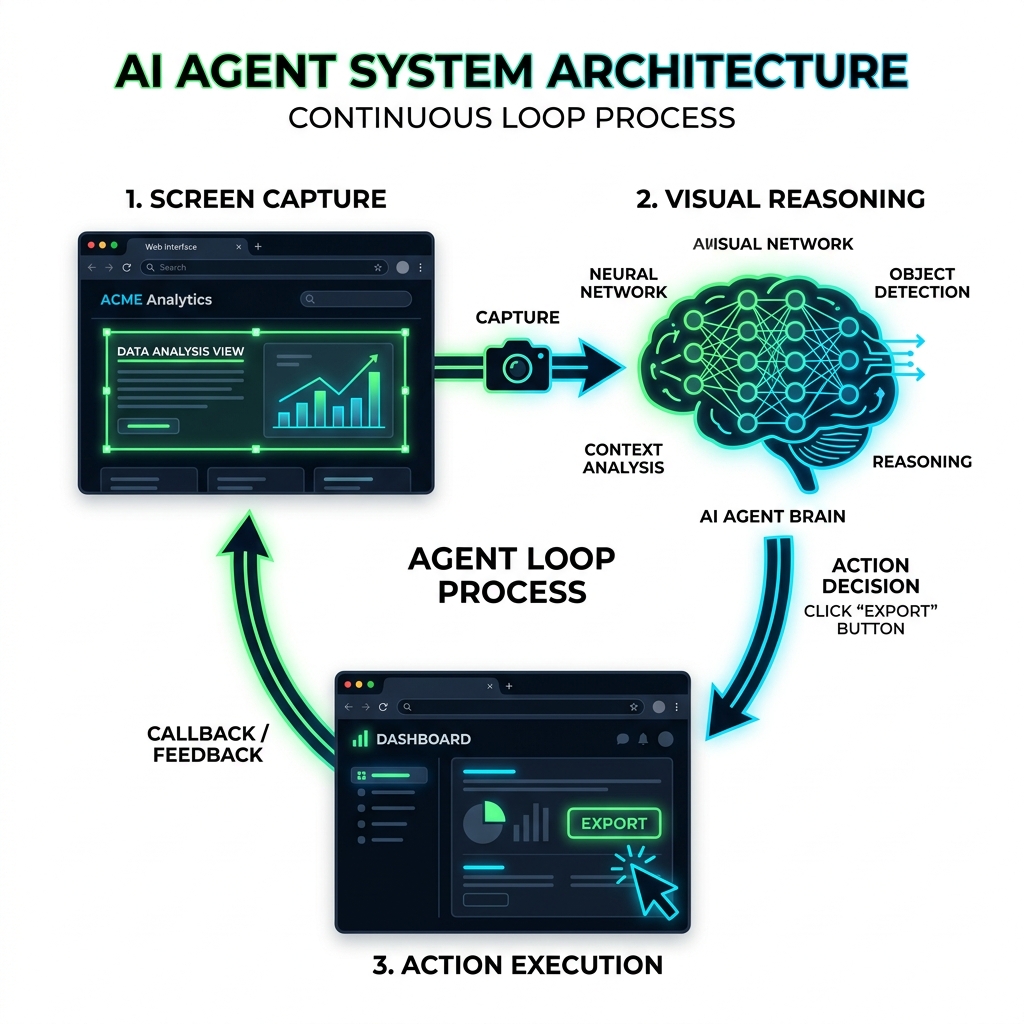
1. 视觉感知:视觉 Token 化 (Visual Tokenization)
AI 并不直接“看”像素点,而是将高分辨率的屏幕截图切分为一系列语义片段。通过视觉编码器,AI 能识别出:
- UI 元素:按钮、文本框、单选框及其层级关系。
- 动态变化:进度条的加载、弹窗的出现、甚至是光标的形状。
2. 语义推理与动作决策
一旦 AI 理解了当前 UI 的状态,它会结合用户的终极目标(Objective)进行分步骤推理(Chain of Thought)。例如,要购买机票,它会先决定“移动光标到搜索框”,然后才是“输入出发地”。
二、 核心难点:坐标对齐与 Action 映射
在 Operator 的开发中,最大的技术难题在于 屏幕坐标的精确映射。
AI 推理出的动作是语义化的(例如:click(search_button)),而执行层需要的是物理坐标(例如:click(x=452, y=310))。
- 坐标变换:Operator 使用了复杂的空间感知算法,确保在不同分辨率、不同缩放比例下,动作依然能够精确落到目标元素上。
- 重试机制:如果一次点击没有触发预期变化,AI 会分析原因(如:被遮挡、页面延迟)并尝试调整坐标或执行重试。
三、 实战案例:跨平台的任务流
让我们看一个 Operator 如何处理典型复杂任务:“帮我调研 3 款竞品,整理到 Google Sheet 中。”
- 观察阶段:打开 Chrome,在 Google 搜索竞品名称。
- 决策阶段:识别并点击最具权威性的链接,提取关键定价。
- 操作阶段:切换 Tab 到已打开的表格,定位到下一行空位,模拟键盘输入数据。
- 校验阶段:检查数据是否完整,然后继续下一款产品的调研。
四、 给独立开发者的 3 条建议
作为开发者,拥抱 Operator 并不是简单地等待 API,而是要预先布局:
1. 优化产品的“AI 可读性”
虽然 CUA 模型很强,但在复杂的、非标准的 UI 界面(如 Canvas 渲染的页面)面前仍会吃力。遵循 WAI-ARIA 等无障碍标准,不仅对残障人士友好,也能显著提升 AI 操控你的产品的成功率。
2. 关注 Token 成本与推理延迟
视觉 Token 的消耗远高于文本。在构建自己的 Agent 应用时,合理的截图频率和分辨率缩放是降低成本的关键。
3. 构建“人机协同”的安全网
不要让 AI 完全脱离监管。在关键的支付、删除操作中,必须设计类似 Operator 的“确认挂起”机制,这不仅是安全需求,更是赢得用户信任的核心。
五、 结语
OpenAI Operator 的出现,标志着操作系统层面的 GUI 自动化 已经进入 2.0 时代。我们正在从“人类操作电脑”转向“人类定义意图,AI 操作电脑”。
作为独立开发者,谁能率先掌握并集成这种“手”的能力,谁就能在 Agent 应用的红海中脱颖而出。
注:本站已上线 OpenClaw 完全指南,探讨如何构建本地化的 AI 助手,欢迎阅读。